dlt uses Apache Arrow to make pipelines faster. The Arrow format is a better way
to represent tabular data in memory than native Python objects (list of dictionaries). It enables
offloading computation to Arrow’s fast C++ library, and prevents processing rows one by one.
Speed matters. Pipelines should move data quickly and efficiently. The bigger the data, the more
that holds true. Growing data volumes force performance optimization upon data processing tools. In
this blog I describe how dlt uses Arrow and why it makes data pipelines faster.
What is dlt?
dlt is an open source Python library that lets you build data pipelines as code. It tries to make
data movement between systems easier. It gives data engineers a set of abstractions (e.g. source,
destination, pipeline) and a declarative API that saves them from writing lower level code.
dlt doesn’t use a backend server/database. It’s “just a library” that can be embedded in a Python
process. pip install dlt and import dlt is all it takes.
An example use case is loading data from a REST API (the source) into a data warehouse (the
destination) with a dlt pipeline that runs in a serverless cloud function (e.g. AWS Lambda).
What is Arrow?
Arrow is an Apache project that standardizes data analytics systems. Among other things, it specifies a format to represent analytics data in memory.
Format characteristics:
language agnostic → it’s the same in C++, Rust, Python, or any other language
columnar → values for a column are stored contiguously
lightweight encoding → no general purpose compression (e.g. Snappy) or complex encodings
O(1) (constant-time) random access
System interoperability and performance are two of the benefits of having this standard.
How dlt works
Before explaining how dlt uses Arrow, I will first describe how dlt works at a high level.
Pipeline steps
A basic dlt pipeline has three main steps:
extract
normalize
load
extract → fetch data from source system and write to local disk
normalize → read extracted data from local disk infer schema and transform data in memory write transformed data to local disk
load → read normalized data from local disk and ingest into destination system
Extraction
extract is I/O intensive.
dlt uses a Python generator function that fetches data from a source system and yields it into the
pipeline. This function is called a resource.
Normalization
Steps 1 and 3 of normalize are I/O intensive. Step 2 is compute intensive. Step 2 has several “substeps”:
identify tables, columns and their data types
apply naming convention (e.g. snake_case) to table and column identifiers
add system columns → e.g.
_dlt_id(row identifier) and_dlt_load_id(load identifier)split nested data into parent and child tables
Some of these substeps are already done during extract when using the Arrow route, as I explain later in this blog.
Loading
Load is I/O intensive (and in some cases also compute intensive).
The data files persisted during normalize are loaded into the destination. How this is done differs per destination.
How dlt uses Arrow
dlt currently supports two different pipeline “routes”:
The traditional route → has existed since earliest versions of
dltThe Arrow route → was added later as improvement
The user decides which route is taken. It’s an implicit choice that depends on the type of object
yielded by the resource.
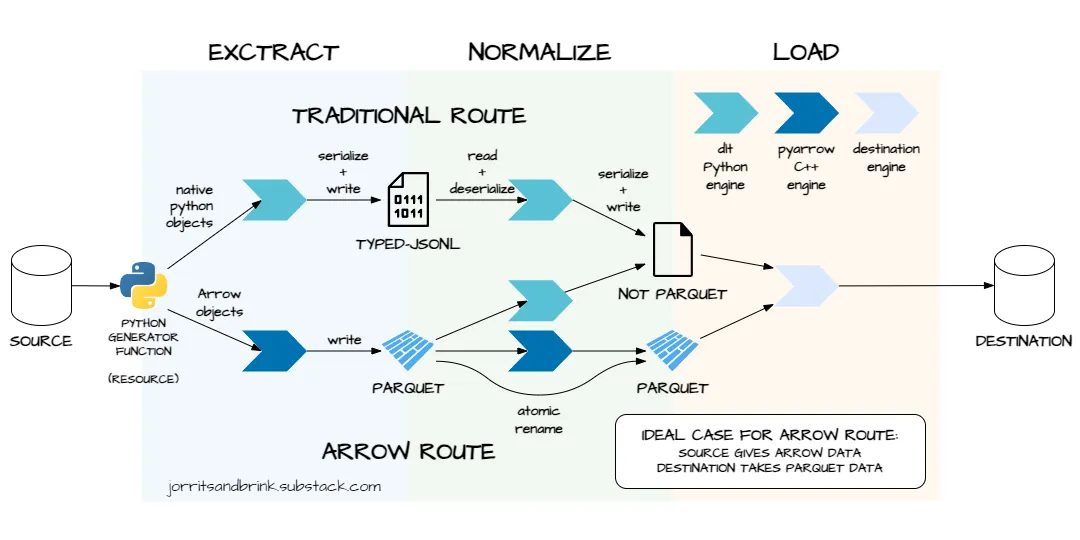
Traditional route
The traditional route uses native Python objects and row orientation to represent tabular data in memory.
@dlt.resource
def my_traditional_resource():
# native Python objects as table
table = [
{"foo": 23, "bar": True},
{"foo": 7, "bar": False}
]
yield table
pipeline.run(my_traditional_resource())
extract
The resource yields Python dictionaries or lists of dictionaries into the pipeline. Each dictionary is a row: keys are column names, values are column values. A list of such dictionaries can be seen as a table.
The pipeline serializes the Python objects into a JSON-like byte-stream (using orjson) and persists to binary disk files with .typed-jsonl extension.
normalize
The pipeline reads the extracted data from .typed-jsonl files back into memory and deserializes it. It iterates over all table values in a nested for loop. The outer loop iterates over the rows, the inner loop iterates over the columns. While looping, the pipeline performs the steps mentioned in the paragraph called Normalization.
The normalized data is persisted to disk in a format that works well for the destination it will be loaded into. For example, two of the formats are:
jsonl → JSON Lines—default for filesystem destination
insert_values → a file storing INSERT SQL statements, compressed by default—default for some of the SQL destinations
load
As mentioned, this step differs per destination. It also depends on the format of the file persisted during normalize. Here are two examples to give an idea:
jsonl files and filesystem destination → use PUT operation
insert_values files and SQL destination (e.g. postgres) → execute SQL statements on SQL engine
Arrow route
The Arrow route uses columnar Arrow objects to represent tabular data in memory. It relies on the pyarrow Python libary.
import pyarrow as pa
@dlt.resource
def my_arrow_resource():
... # some process that creates a Pandas DataFrame
# Arrow object as table
table = pa.Table.from_pandas(df)
yield table
pipeline.run(my_arrow_resource())
extract
The resource yields Arrow objects into the pipeline. These can be Arrow tables (pyarrow.Table) or Arrow record batches (pyarrow.RecordBatch). Arrow objects are schema aware, meaning they store column names and data types alongside the data.
The pipeline serializes the Arrow objects into Parquet files on disk. This is done with pyarrow’s Parquet writer (pyarrow.parquet.ParquetWriter). Like Arrow objects, Parquet files are schema aware. The Parquet writer simply translates the Arrow schema to a Parquet schema and persists it in the file.
The yielded Arrow objects are slightly normalized in the extract step. This prevents a rewrite in the normalize step. The normalization done here are cheap metadata operations that don’t add much overhead to extract. For example, column names are adjusted if they don’t match the naming convention and column order is adjusted if it doesn’t match the table schema.
normalize
Schema inference is not needed because the table schema can be read from the Parquet file.
There are tree cases—in the ideal case, data does not need to be transformed:
destination supports Parquet loading — no normalization (ideal): the extracted Parquet files are simply “moved” to the load folder using an atomic rename. This is a cheap metadata operation. Data is not transformed and the data doesn’t actually move.
dltdoes not add row and load identifier columns.destination supports Parquet loading — yes normalization (okay): the extracted Parquet files are loaded into memory in Arrow format. The necessary transformations (e.g. adding system columns or renaming column identifiers) are done using pyarrow methods. These operations are relatively cheap. Parquet and Arrow are both columnar and have similar data layouts. Transformations are done in batch, not on individual rows. Computations are done in C++, because pyarrow is a wrapper around the Arrow C++ library.
destination does not support Parquet loading (not good): the extracted Parquet files are read in memory and converted to a format supported by the destination (e.g. insert_values). This is an expensive operation. Parquet’s columnar format needs to be converted to row orientation. The rows are iterated over one by one to generate the load file.
load
This step is the same as in the traditional route.
Main differences
The most important differences between the traditional and Arrow routes are as follows.
in memory format
- traditional → native Python objects
- Arrow → pyarrow objects
on disk format for normalized data
- traditional → defaults to jsonl
- Arrow → defaults to parquet
schema inference
- traditional → handled by
dltduring normalize—done in Python while iterating over rows - Arrow → two cases:
- source system provides Arrow data: schema taken from source (no schema inference needed)
- source system does not provide Arrow data: handled by pyarrow during extract when data is converted into Arrow objects, done in C++
- traditional → handled by
data transformation for normalization
- traditional → handled by dlt—done in Python while iterating over rows
- Arrow → handled by pyarrow—done in C++ on columnar batches of rows
Why dlt uses Arrow
dlt uses Arrow to make pipelines faster. The normalize step in particular can be much more efficient
in the Arrow route.
Using pyarrow objects for tabular data is faster than using native Python objects (lists of dictionaries), because they are:
schema aware
columnar
computed in C++
Generally speaking, C++ is much faster than Python. Moreover, Arrow’s C++ implementation can use
vectorization (SIMD) thanks to the columnar data layout. The Arrow route can process batches of
values concurrently in C++, while dlt’s traditional route needs iteration over values one by one in
a nested Python loop.
Schema aware Arrow objects prevents dlt from having to infer column types from column values.
Further thoughts
A potential optimization I can think of (but haven’t tested) is to use the Arrow IPC File Format to serialize data between extract and normalize. This saves two format conversions:
Arrow → Parquet (serialization at the end of extract)
Parquet → Arrow (deserialization at the start of normalize)
Although Arrow and Parquet have relatively similar layouts (especially when using Parquet without general purpose compression), removing the (de)serialization steps might still improve performance significantly.
Simply disabling compression when writing the Parquet file could be an easier way to achieve similar results.
Context
I contribute to the open source dlt library, but didn’t implement the core framework logic related
to extraction, normalization, and loading described in this post. I’m enthusiastic about Arrow and
its implications for the data ecosystem, but haven’t contributed to their open source libraries.
Call to action
Try the SQL connector here with the various backends: Docs
Want to discuss performance? Join the dlt slack community!