
Hi there! 👋
In this article, we asked ChatGPT questions about dlt, the open source library. Questions included some basic introduction, random fun questions, and advanced dlt project processes. Let’s see how it answered our questions!
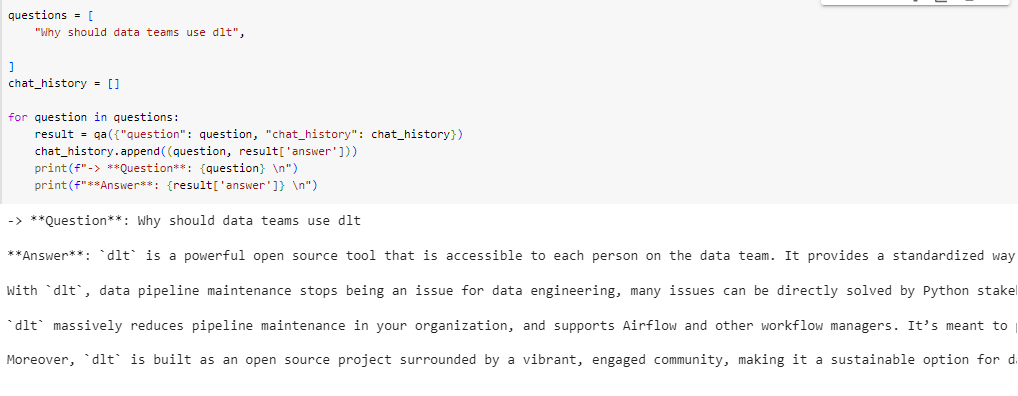
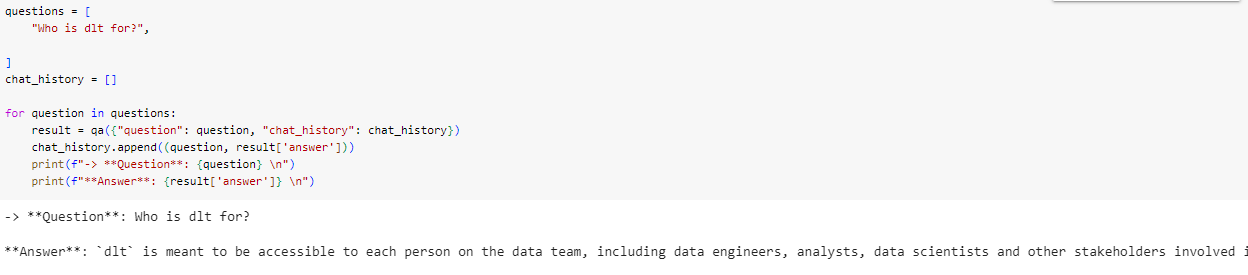
💡 Who can use dlt?
dltis designed to be accessible and useful for various roles within a data team, including:
Data professionals and aspiring data professionals who want to showcase their understanding and value to data teams. They can use
dltto build end-to-end projects, load data to databases, transform data, and prepare reporting. Read more in the Data Beginner guide.Data engineers who want to remove tedious work, reduce ETL maintenance, empower their team members, and enhance their productivity.
dltcan be used to automate data loading, enable collaboration, and support natural workflows. Read more in the Data Engineer guide.Data analysts, data scientists, and analytics engineers who want to build and use pipelines for single use cases, core business pipelines, or heavily customized pipelines.
dltoffers different levels of abstraction to cater to various needs and use cases. Read more in the Data Beginner guide.Overall,
dltis suitable for anyone working with data pipelines, from beginners to experienced professionals.
💡 I am just starting in the data field, how can I use dlt?
If you are just starting in the data field,
dltcan be a great tool to help you showcase your understanding and value to data teams. The first step is to get familiar withdltby playing around with the Google Colab demo or installing it on your computer. Once you havedltinstalled, you can initialize a project and pipeline to load data from an API, transform it, and load it into a database in minutes.
💡 How can data scientists use dlt in data science projects?
Data scientists can use
dltin data science projects to easily load and transform data from various sources.dltoffers different levels of abstraction that enable and empower data scientists to build and use pipeline.For example, data scientists can use
dltto build pipelines for their specific use cases, such as grabbing data from an API that they need for their analysis. They can heavily customize howdltsources produce data, such as selecting, filtering, renaming, anonymizing, and just about any custom operation.In addition, data scientists can use
dltto create highly scalable, easy to maintain, straightforward to deploy data pipelines without having to wait for help from a data engineer. This empowers them to turn messy, unstructured data into regularly updated datasets and focus on their analysis and modeling work. Overall,dltcan help data scientists be more efficient and productive in their work by simplifying the data loading process and allowing them to focus on the analysis and modeling.
Now, let’s start with some advanced questions:
💡 Is dlt like dbt? How to use dlt with dbt? Can you show me the process?
Yes,
dltanddbthave similar functionalities, but they differ in their approach and scope.dltis a Python package that helps you load data from various sources and transform it to be ready for analysis.dbt, on the other hand, is a SQL transformation tool that allows you to structure and transform your data using SQL. However, you can usedltwithdbtto create a complete data pipeline from data extraction to transformation and loading. Here is an example process to usedltwithdbt:To use
dbtwithdlt, you can follow these steps:
- Install
dbtanddltusing pip.- Create a
dltpipeline to extract, transform, and load data into your data warehouse. You can use thedltSQL client to create tables, views, and other structures that can be used for analysis.- Create a
dbtproject and configure it to use the same data warehouse as yourdltpipeline.- Write SQL queries to transform the data in your
dbtproject.- Run the
dbtproject to create the necessary structures and transformations in your data warehouse.- Use a BI tool to visualize and analyze the transformed data.
Overall, using
dltwithdbtcan help you create a complete data pipeline that covers data extraction, transformation, and loading. This can help you streamline your data processes and make it easier to analyze your data.
💡 Can I use dlt with Streamlit? Or Sheets? Or Power BI? Metabase, Looker? What do you recommend?
Yes,
dltcan be used with Streamlit, Google Sheets, Power BI, Metabase, and Looker. The choice of tool will depend on your specific use case and requirements. For example, if you want to enable business users to explore data and create their own dashboards, then Metabase or Looker might be a good choice.If you want to build a custom dashboard with Python, then Streamlit might be a good choice. If you want to use a cloud-based BI tool, then Power BI might be a good choice. In terms of using
dltwith these tools,dltcan be used to load data into a database or data warehouse that can then be connected to these tools. For example, you can usedltto load data into a PostgreSQL database and then use that database as a data source for Power BI.Overall, I would recommend using the tool that best fits your specific use case and requirements, and then using
dltto load and transform your data as needed.
💡 How can I use dlt to create a machine learning model?
dltcan be used to create machine learning models in the following way:
- Choose an API that produces data.
- Choose a use case for this data.
- Build a
dltpipeline that loads data from the API for your use case.- Extract data from your pipeline. 5>. Create a machine learning model depends on your use case.
- Finally, you can deploy your model with Metabase dashboard.
Let’s try trolling :)
💡 I am tired of lakehouses, can I build a beach house with dlt? or a forest house??
I am sorry, but
dltis a data loading tool, and it is not related to building beach houses. It is meant to help you automate the process of loading and managing data in your applications. If you have any questions related to data loading or management, I will be happy to help!
💡 If data is the new oil, then what is dlt? newer oil?
dltis not a type of oil. It is a data loading tool that automates time-consuming tasks, empowers stakeholders to solve pipeline maintenance issues, and offers different levels of abstraction that enable and empower data professionals to build and use pipelines. Its purpose is to make data loading a commodity and to simplify the process of loading data for organizations.
💡 Conclusion
We intended to ask ChatGPT different questions about
dltand see if there are any misunderstandings. For example: howdltcan be intergrated in various use cases or how data teams can usedltin different projects. Seems it worked really well and answered our questions precisely based on our documentation and blog! Moreover, when we tried to ask some random questions, ChatGPT also gave us proper answers! GPT really seems to understands what we were trying to communicate with it!
What questions you would love to ask? Share with us in our Slack community ! See you there 😊
[ What's more? ]
- Learn more about
dlt👉 here - Give the 👉 Colab Demo a try



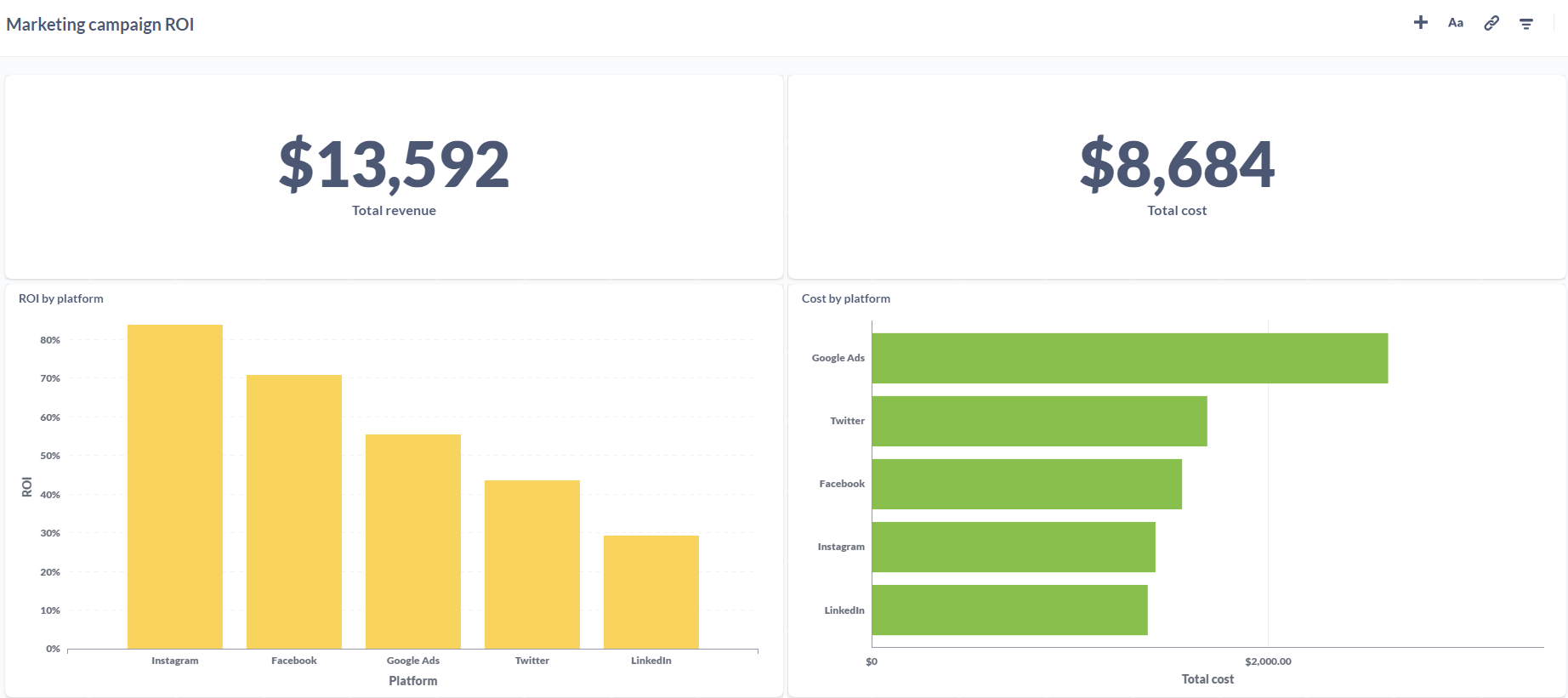
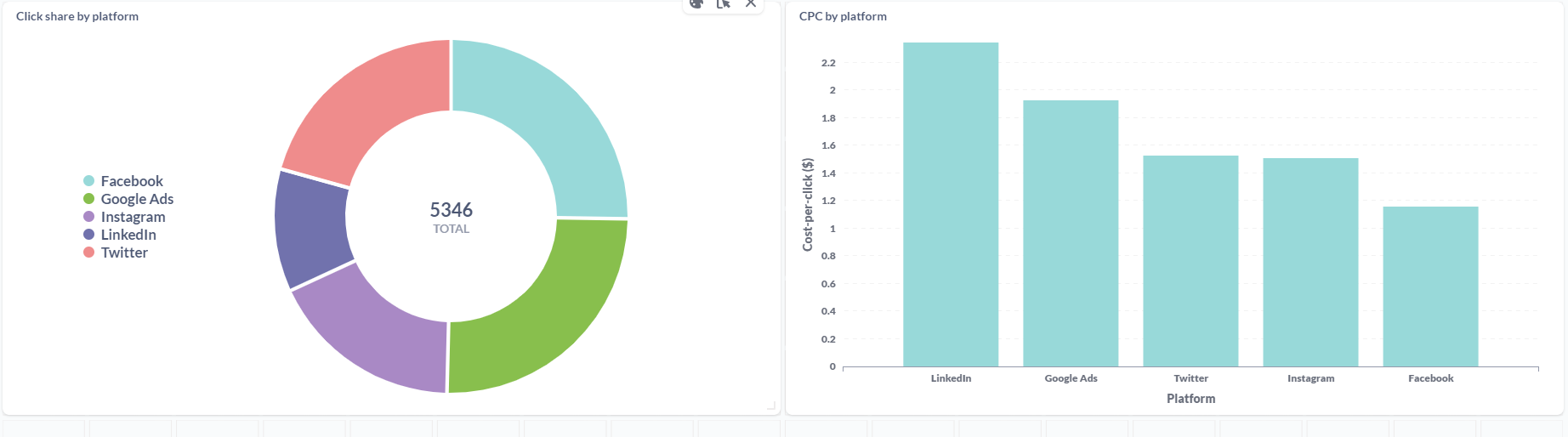
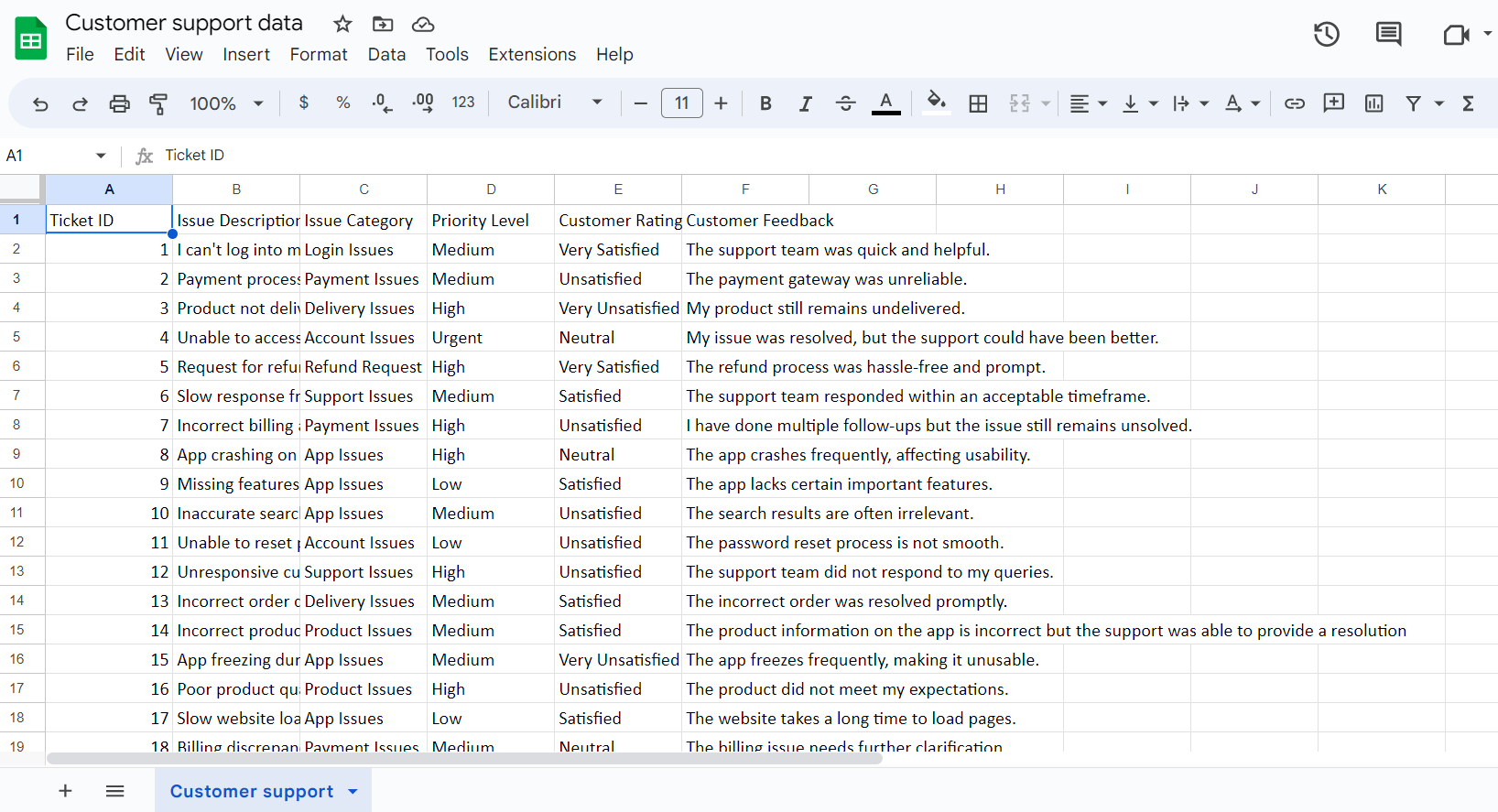
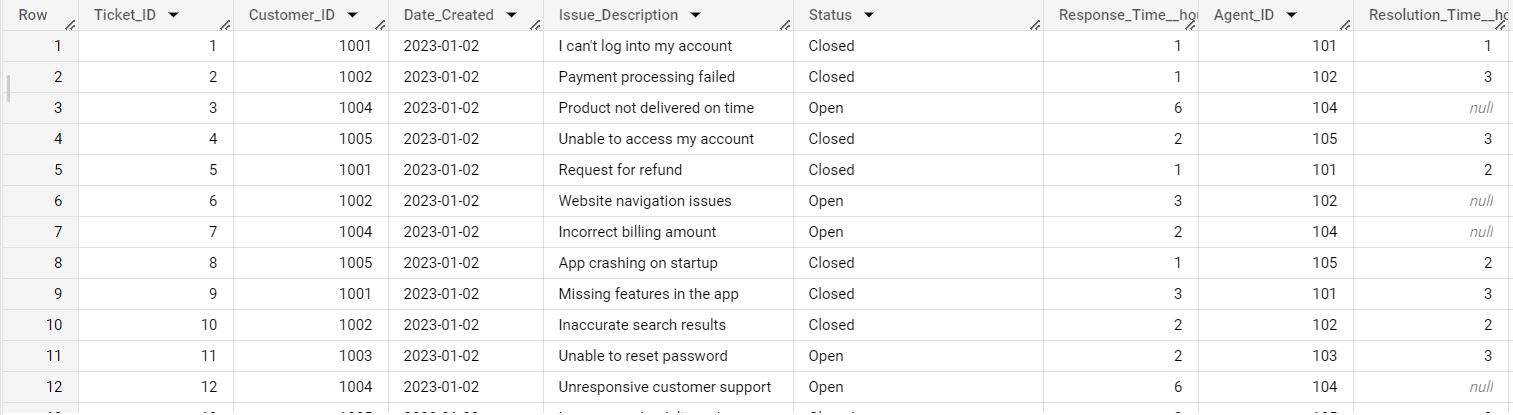
 In addition to this, we were also able to set up email alerts to get notified whenever the stock of a DVD was either empty or close to emptying.
In addition to this, we were also able to set up email alerts to get notified whenever the stock of a DVD was either empty or close to emptying.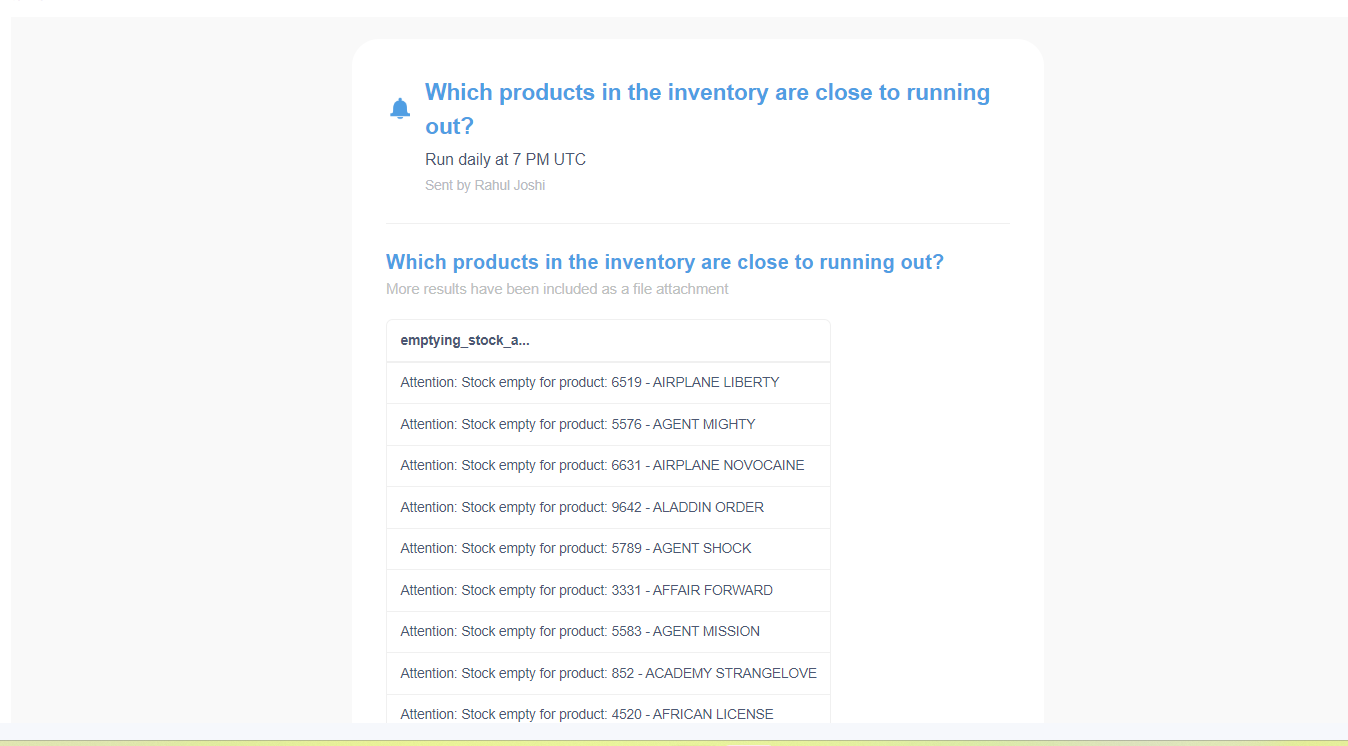
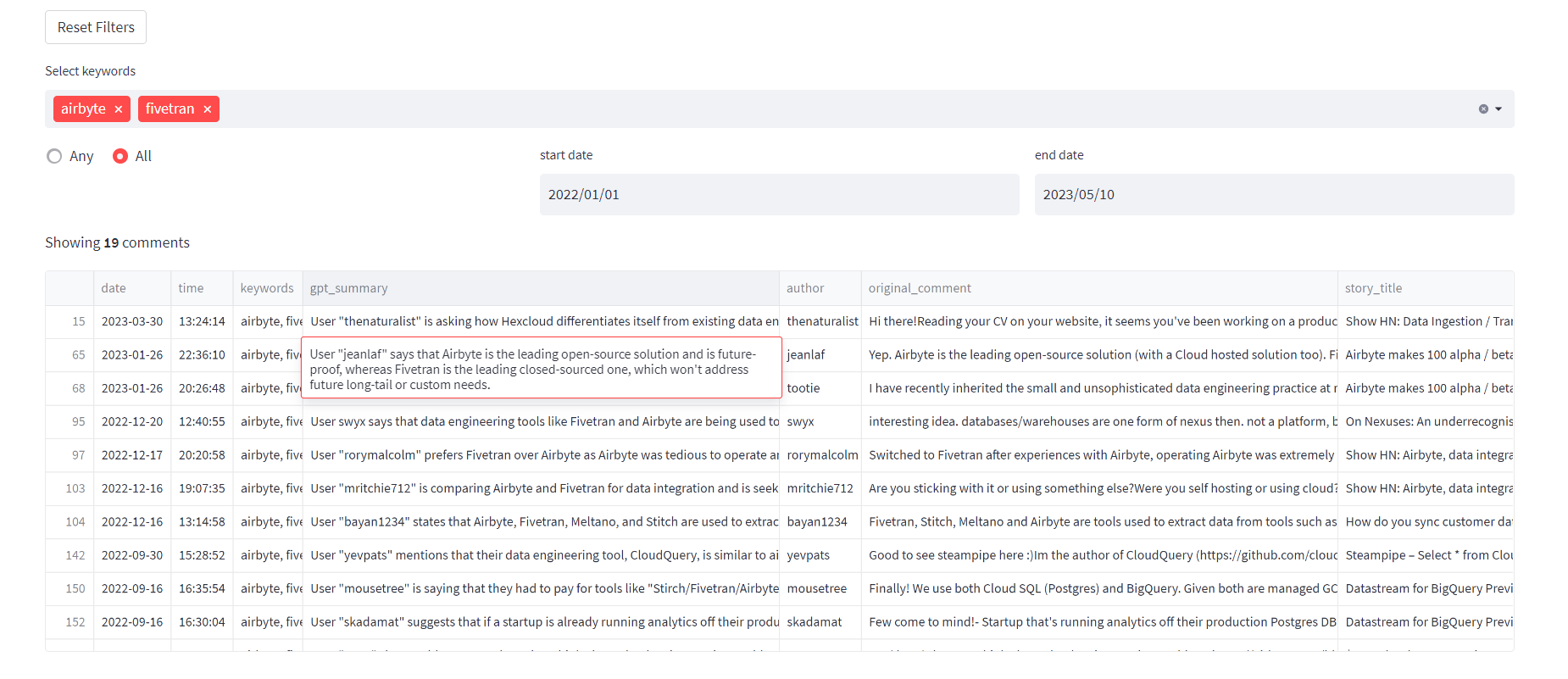
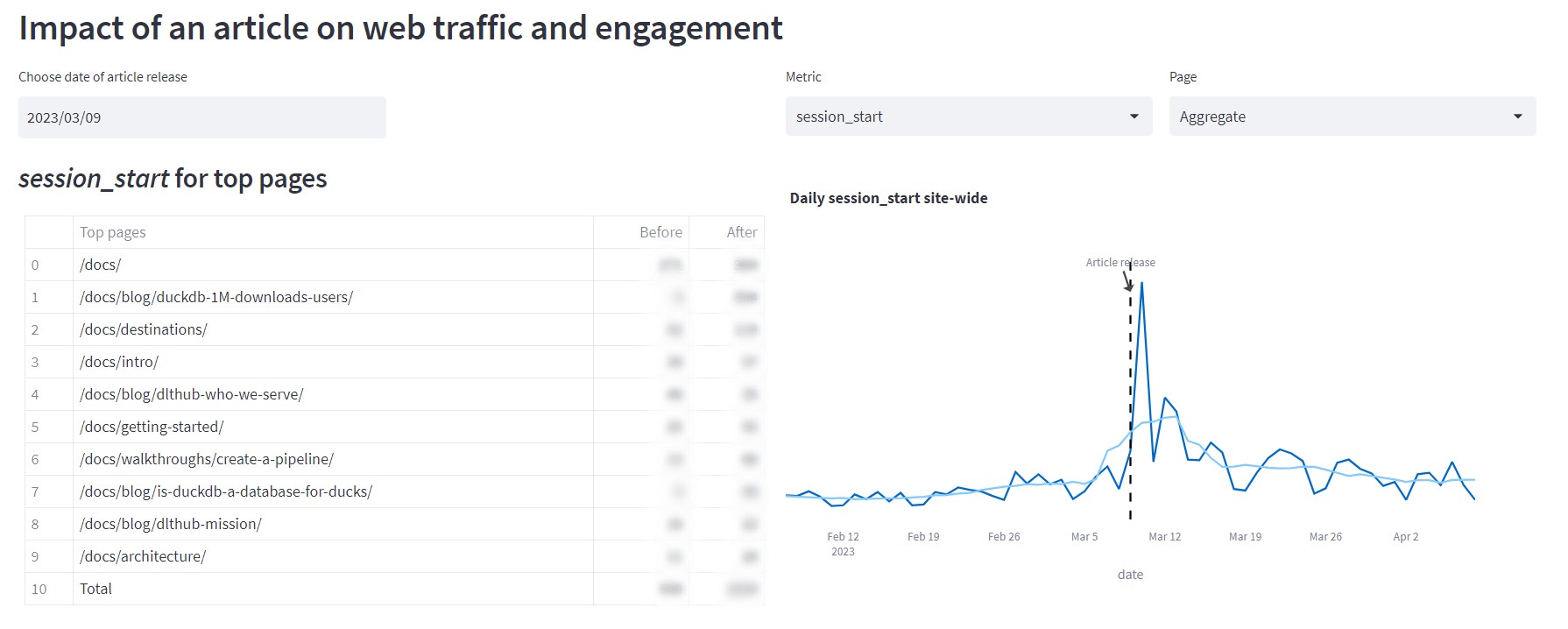
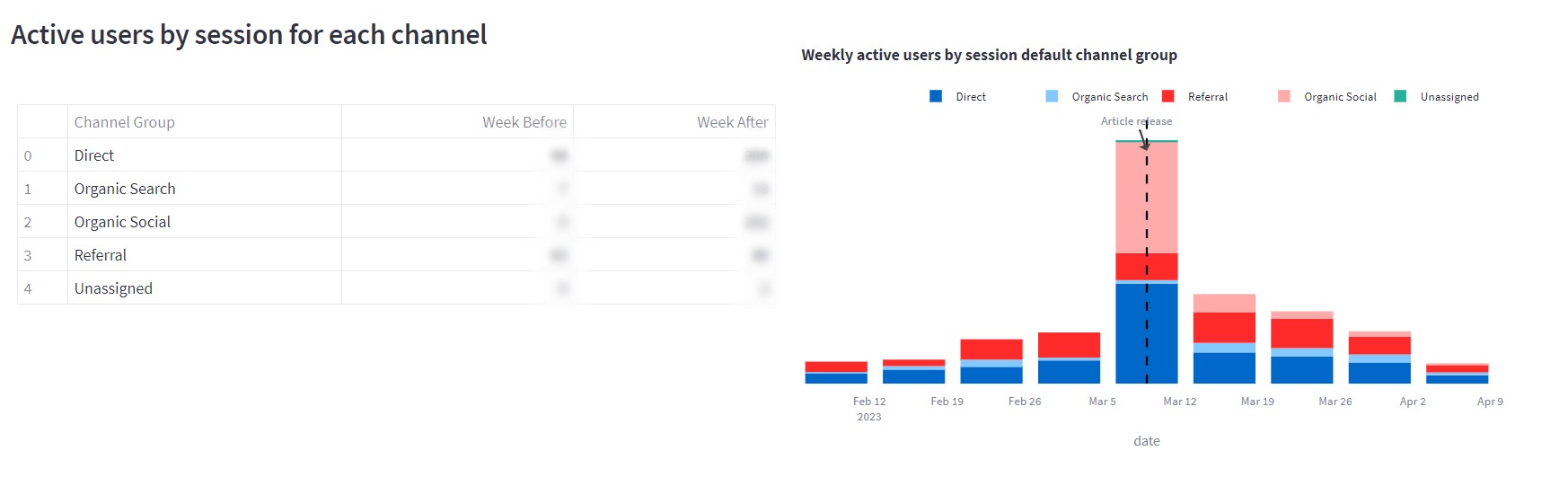

 Source:
Source: